Does NeMo Safe Synthesizer Actually Work? A Case Study with Financial Transactions Data¶
NeMo Safe Synthesizer creates private, safe versions of sensitive tabular datasets: entirely synthetic data with no one-to-one mapping to the original records, while preserving the statistical structure to remain useful for downstream AI and analytics.
That promise sounds simple, but it raises the question every synthetic data system eventually has to answer: does it actually work?
For NeMo Safe Synthesizer, "working" means satisfying two requirements at the same time:
- Privacy: Does the synthetic data avoid direct memorization of transaction rows?
- Fidelity: Does it preserve the data structure and behavioral patterns in the source data?
The tension between privacy and fidelity is the interesting part. A dataset that merely avoids copying records is private, but not necessarily useful. A dataset that captures every pattern too literally may be useful, but has higher risk of leaking sensitive aspects of the original. In this dev note, we walk through a concrete financial transactions example and check both sides of that tradeoff.
The full tutorial notebook contains the runnable workflow, including prerequisites and setup.
Dataset¶
The dataset is a synthetic account transaction ledger with 3,980 transaction detail rows. Each row represents a transaction, with columns such as:
acct_id: account identifier used to group transactions into sequencescardholder: cardholder namestate: US statetxn_index: sequence order within the accounttimestamp: transaction timemerchant_cat: merchant categorymerchant: merchant nametxn_amount: transaction amount
This dataset was generated for the case study so we could evaluate known transaction patterns without using real financial customer data.
Here is a preview of the source data:
| acct_id | cardholder | state | txn_index | timestamp | merchant_cat | merchant | txn_amount |
|---|---|---|---|---|---|---|---|
ACCT-013E4482 |
Alexis Parsons | CA | 1 | 2025-01-02 21:20:56 | entertainment | AMC Theatres | 158.40 |
ACCT-013E4482 |
Alexis Parsons | CA | 2 | 2025-01-03 09:55:05 | subscription | Spotify | 12.99 |
ACCT-013E4482 |
Alexis Parsons | CA | 3 | 2025-01-03 10:49:25 | healthcare | Walgreens | 1529.73 |
ACCT-013E4482 |
Alexis Parsons | CA | 4 | 2025-01-03 17:05:01 | retail | Best Buy | 94.89 |
ACCT-013E4482 |
Alexis Parsons | CA | 5 | 2025-01-04 00:00:07 | subscription | Netflix | 12.99 |
Running NeMo Safe Synthesizer¶
The code snippet below runs NeMo Safe Synthesizer using the Python SDK with the original financial transactions dataset as the only required input file. Because transaction history is inherently sequential, the configuration tells NeMo Safe Synthesizer to group rows by acct_id and order each account's transactions by txn_index.
from nemo_safe_synthesizer.sdk.library_builder import SafeSynthesizer
builder = (
SafeSynthesizer(save_path=ARTIFACT_ROOT)
.with_data_source(source_df)
.with_data(
holdout=0,
group_training_examples_by="acct_id",
order_training_examples_by="txn_index",
)
.with_replace_pii(enable=True)
.with_train(
pretrained_model="HuggingFaceTB/SmolLM3-3B",
num_input_records_to_sample=60000,
learning_rate=5.0e-4,
lora_r=32,
)
.with_time_series(is_timeseries=True, timestamp_column="txn_index")
)
builder.run()
results = builder.results
The results below come from one run of the tutorial notebook. Exact values and plots will vary across runs, which is expected for synthetic generation, but the same checks apply.
This run produced 3,919 transaction detail rows. The original and synthetic datasets both contained 50 account groups, with a median of 79 transactions per original account and 80 transactions per synthetic account. In other words, NeMo Safe Synthesizer generated a dataset with roughly the same scale and sequence structure as the source.
Here is a sample of the synthetic output:
| acct_id | cardholder | state | txn_index | timestamp | merchant_cat | merchant | txn_amount |
|---|---|---|---|---|---|---|---|
ACCT-013E4482 |
Nicholas Myers | CA | 4 | 2025-01-03 19:40:55 | dining | McDonald's | 46.79 |
ACCT-013E4482 |
Nicholas Myers | CA | 5 | 2025-01-04 05:51:48 | subscription | Netflix | 4.99 |
ACCT-013E4482 |
Nicholas Myers | CA | 6 | 2025-01-04 11:59:45 | travel | Delta Air Lines | 397.51 |
ACCT-013E4482 |
Nicholas Myers | CA | 7 | 2025-01-04 18:03:35 | dining | Starbucks | 46.99 |
ACCT-013E4482 |
Nicholas Myers | CA | 8 | 2025-01-05 21:31:36 | e-commerce | Amazon | 62.21 |
Built-In Evaluation¶
NeMo Safe Synthesizer generates a built-in evaluation summary after generation. Scores are reported on a 0--10 scale, where higher is better.
Quality:
| Metric | Score |
|---|---|
| Synthetic Data Quality Score | 9.7 |
| Column Correlation Stability | 10.0 |
| Deep Structure Stability | 9.2 |
| Column Distribution Stability | 9.7 |
Privacy:
| Metric | Score |
|---|---|
| Data Privacy Score | 9.8 |
| Attribute Inference Protection | 9.8 |
The headline numbers are strong. Quality and privacy scores are high. The next question is use-case specific: do the general-purpose evaluation metrics line up with the patterns that matter for this transaction dataset?
Question 1: Did NeMo Safe Synthesizer Memorize Rows or Groups?¶
The first test is whether synthetic records duplicate the source. The answer is no:
- Exact transaction row overlap: 0.0%
cardholdervalue overlap: 0.0%
There were no duplicate transaction rows, and no cardholder names from the source appeared in the generated data. NeMo Safe Synthesizer produced novel rows rather than a row-for-row copy of the input.
We also checked whether account-level metadata could make an account stand out even after row-level values and cardholder names changed:
| Account-level signal | Result |
|---|---|
| Accounts compared | 50 |
| Exact transaction-count matches | 3 |
| Accounts with absolute delta <= 5 transactions | 21 |
| Accounts with absolute delta <= 10 transactions | 38 |
| Median absolute transaction-count delta | 7 |
| Max absolute transaction-count delta | 28 |
| Exact high-value transaction-count matches | 14 |
| Median absolute total-spend delta | $3,350 |
Transaction counts and amount summaries (comparison not shown) varied enough between original and synthetic account histories that there was no obvious one-to-one match from those signals alone.
Question 2: Did NeMo Safe Synthesizer Preserve the Patterns?¶
Privacy alone is not enough. Synthetic data is useful only if it keeps the structure that downstream users care about. For this transaction dataset that might be category mix, time-of-day behavior, amount distributions, and the relationships between those fields.
This is where the financial transactions example becomes a better test than a simple flat table. We intentionally care about sequences and behavioral patterns, not just whether each column or row looks plausible in isolation.
Category Mix¶
The first target is merchant category mix:
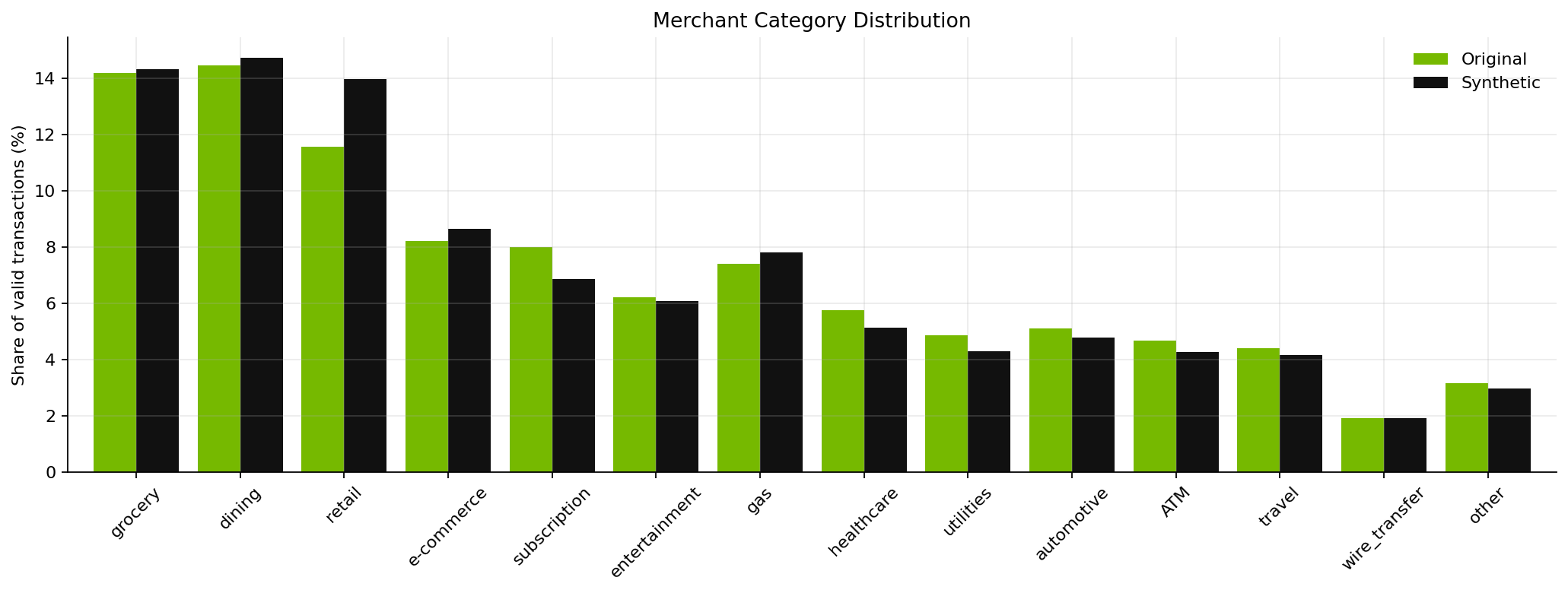
The synthetic distribution preserves the intended shape. High-frequency categories remain high frequency, low-frequency categories remain low frequency, and wire transfers remain rare.
That matters because downstream uses are not just looking for valid strings in the merchant_cat column. They need a plausible transaction portfolio. A model trained on a flattened or arbitrary category distribution would learn the wrong baseline behavior before it ever reached a more advanced task.
Time-of-Day Behavior¶
Next, we checked whether category-specific time patterns survived. This is a stronger test than a simple column distribution because NeMo Safe Synthesizer must preserve a relationship between merchant_cat and timestamp.
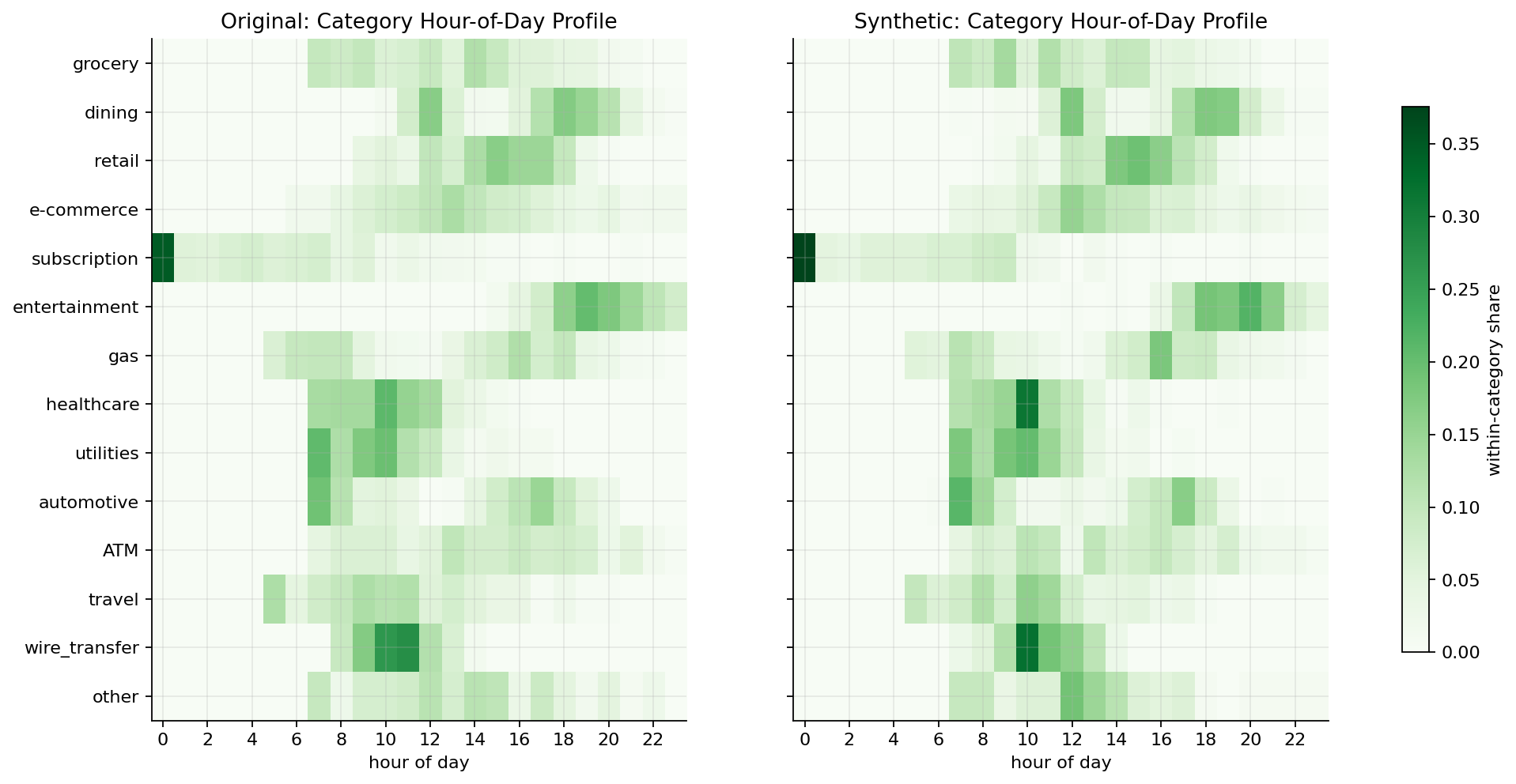
The synthetic heatmap keeps the major temporal signatures:
- Dining is concentrated later in the day, with lunch/dinner behavior.
- Entertainment stays in the evening.
- Healthcare and wire transfers remain closer to business hours.
- Subscriptions remain much more likely to appear overnight than most other categories.
This is a good example of what "utility" means in practice. The goal is not merely to generate realistic timestamps. The goal is to preserve when different kinds of transactions tend to happen.
Amount Distributions¶
Financial datasets are dominated by tails: most transactions are small, but a few categories create high-value transactions. Synthetic data needs to preserve that shape or downstream analytics will be misleading.
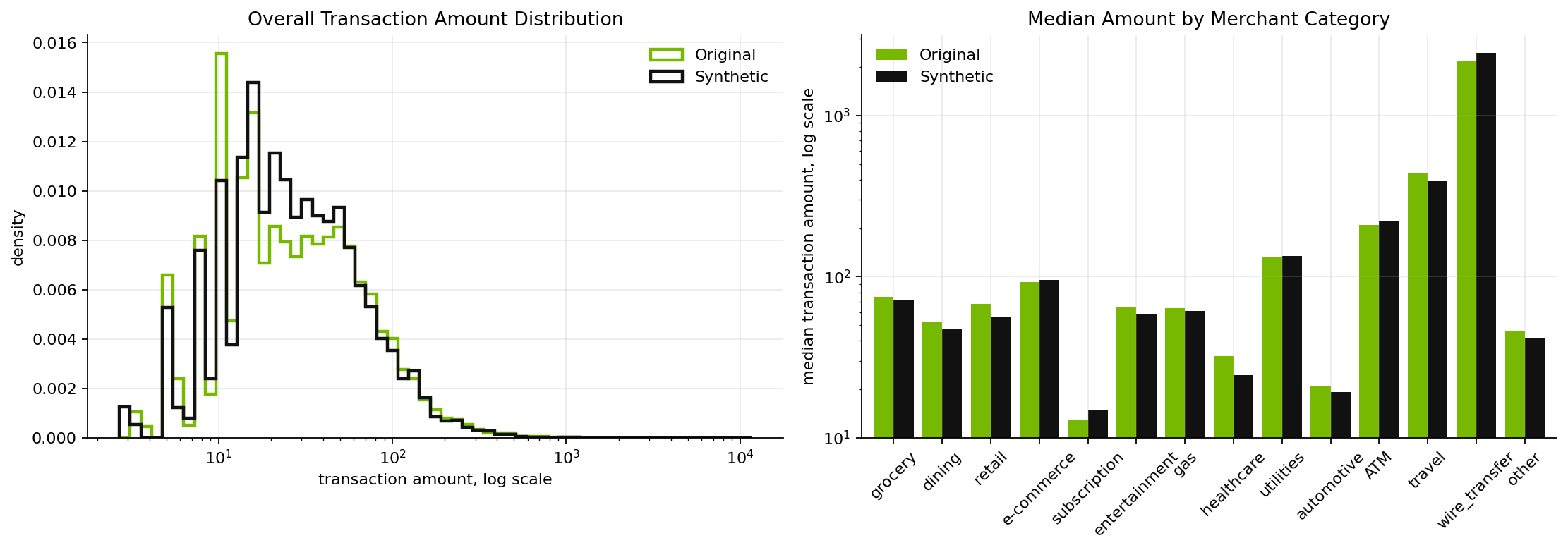
The overall distribution is close:
- Median amount:
$68.21original vs.$61.87synthetic - 90th percentile:
$278.16original vs.$249.64synthetic - 99th percentile:
$2,066.39original vs.$2,384.10synthetic
The central mass is close, and the high-value tail remains in the right range. That is especially important for financial use cases, where risk models, anomaly detection, and forecasting workflows are often sensitive to rare but high-impact transactions.
So, Does It Work?¶
I hope after reading this article, your answer is Yes!
NeMo Safe Synthesizer produced novel synthetic rows and transaction sequences, achieved high privacy scores, and preserved statistical patterns in the source data. The synthetic dataset is best understood as another sample from the same broader transaction population: individual values will differ from the source sample, but the category mix, timing behavior, and amount distributions should remain within a useful range.
That is the practical promise of safe synthetic data: not a perfect clone, and not random fake data, but a privacy-aware substitute that retains enough signal for meaningful development, analysis, and model experimentation.
Next Steps¶
The full financial transactions notebook contains the runnable NeMo Safe Synthesizer job, prerequisites, analysis code, and chart generation used in this dev note.
Have questions or want to share what you are building? Open a GitHub discussion or file a feature request.